小米首個推理大模型開源 數(shù)學(xué)與代碼測評超越OpenAI
4月30日,小米公司于“Xiaomi MiMo”公眾號正式宣布開源其首個專注于推理能力的大模型「Xiaomi MiMo」。小米官方表示,該模型以7B(70億)參數(shù)規(guī)模,在數(shù)學(xué)推理(AIME 24-25)和代碼競賽(LiveCodeBench v5)等公開測評中表現(xiàn)優(yōu)異,超越OpenAI的閉源模型o1-mini及阿里Qwen2.5-32B等更大規(guī)模的開源模型。

小米技術(shù)團(tuán)隊表示,MiMo的核心突破在于預(yù)訓(xùn)練與后訓(xùn)練階段的協(xié)同優(yōu)化。在預(yù)訓(xùn)練階段,模型通過挖掘高質(zhì)量推理語料并合成約2000億tokens專項數(shù)據(jù),采用三階段漸進(jìn)訓(xùn)練策略,累計訓(xùn)練量達(dá)25萬億tokens。

后訓(xùn)練階段則引入創(chuàng)新強(qiáng)化學(xué)習(xí)技術(shù),包括自研的"Test Difficulty Driven Reward"算法和"Easy Data Re-Sampling"策略,有效提升模型在復(fù)雜任務(wù)中的穩(wěn)定性。技術(shù)團(tuán)隊還開發(fā)了"Seamless Rollout"系統(tǒng),使訓(xùn)練效率提升2.29倍,驗證速度加快1.96倍。

值得注意的是,小米官方表示,MiMo-7B在相同強(qiáng)化學(xué)習(xí)訓(xùn)練數(shù)據(jù)下,數(shù)學(xué)與代碼領(lǐng)域的表現(xiàn)顯著優(yōu)于當(dāng)前業(yè)界廣泛使用的DeepSeek-R1-Distill-7B和Qwen2.5-32B模型。
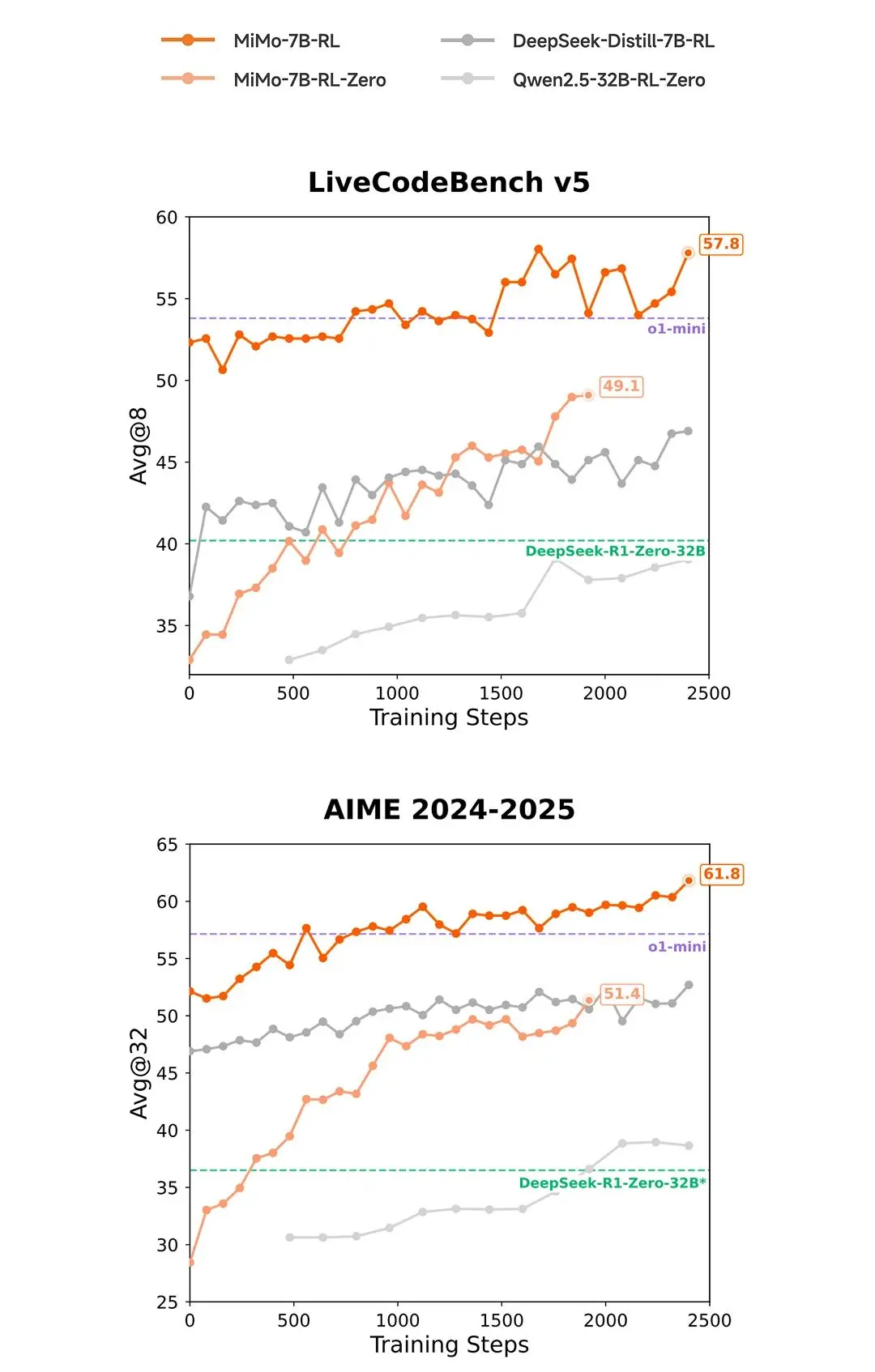

目前,小米已在HuggingFace平臺開源MiMo-7B全系列4個模型,并發(fā)布詳細(xì)技術(shù)報告。
【來源: 鳳凰網(wǎng) 科技 】












